Design Overview
The above schema depicts the overall architecture of NFStream composed of 3 main components: NFStreamer, a set of parallel Flow Meters, and a socket information collector. In what follows, we briefly describe the main functions of these components.
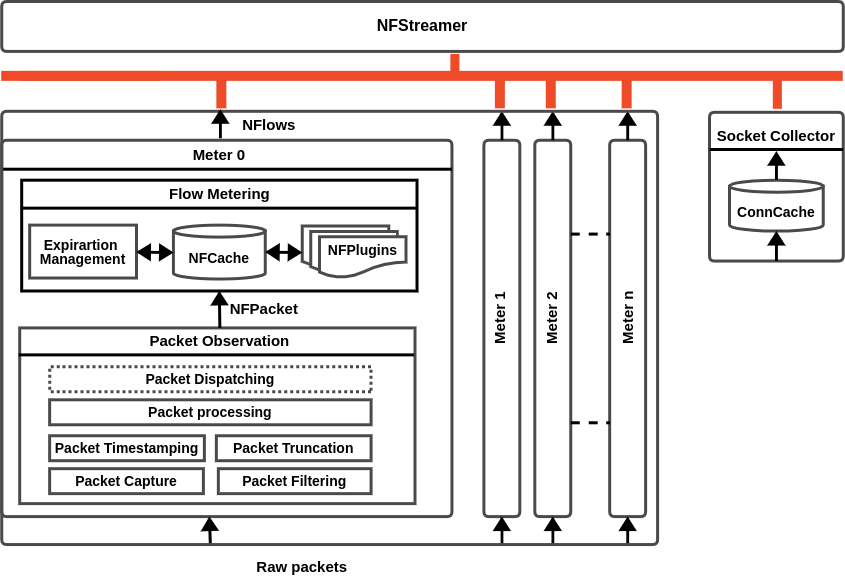
Table of contents
Meter
Packet Observation
The packet observation layer is destined to observe packets from online and offline traffic capture. This layer is implemented in C and bound to Python using C Foreign Function Interface CFFI. This implementation choice allows for performing several packet-related processes efficiently while exposing a unique NFPacket Python object. Moreover, CFFI is highly optimized for the usage of PyPy.
Packet capture
Packet capture is enabled on the network interface card level. After passing various checksum error checks, the packets stored in on-card reception buffers are moved to the hosting device memory. Several libraries are available to capture network traffic. The most popular are libpcap, destined for UNIX-based operating systems, and winpcap for Windows. NFStream implements a modified version of libpcap library that is used for online and offline modes on UNIX-based operating systems. On Windows, it uses NPCAP, a maintained (by nmap project) version of WinPcap.
Packet truncation
Packet truncation is destined for selecting precise bytes from the captured packet (e.g., snapshot length). It is also used to reduce the amount of data captured, which leads to reduced CPU and bus bandwidth load.
Packet timestamping
Packet timestamping is mandatory as packets may come from several observation points. NFStream relies on software packet timestamping, which provides milliseconds accuracy.
Packet filtering
Packet filtering serves packet filtering based on a set of characteristics. A packet is selected if the specific fields are equal or in the range of the given values. NFStream packet filtering is based on the Berkeley Packet Filter (BPF) syntax. BPF provides a kernel-based interface to the link and network layers. Its features make it highly efficient at processing and filtering packets. A user-mode interpreter for BPF is provided with the libpcap implementation of the pcap API, so programmers can write applications that transparently support a rich set of constructs to build detailed packet filtering expressions for network protocols.
Packet processing
Packet processing consists of a set of parsers that allow NFStream to decode the packet and extract its attributes as part of the NFPacket object, which is the shared object between the packet observation layer and the metering layer of each meter process.
Packet dispatching
Packet dispatching consists of load-balancing packet processing across parallel metering processes. On Linux, the load balancing feature is pushed down to the kernel using the AF_PACKETv3 FANOUT feature. However, both online mode and offline modes require load balancing in userspace. NFStream achieves such a task by computing a flow-aware hash for each packet. If the calculated hash matches the meter identifier, the packet is consumed. Otherwise, it is used only as a time ticker. This heuristic is also used for non-Linux online capture.
Flow Metering
The flow metering layer implements the flow measurement logic of NFStream. Its primary functions include aggregating packets into flows, flow feature computation, and flow expiration management.
NFCache
NFCache stores the entries in a hash map and maintains a least recently used doubly linked list of entries. Flow metering uses these structures to store information regarding active flows. A flow hash determines whether an NFPacket matches an existing entry or not. In the case of a match, the flow features are updated. Otherwise, a new entry is created and initiated. A flow entry is considered bidirectional if its address port pair and its reverse belong to the same entry.
Expiration management
Expiration management runs on top of three flow termination logics. The first is active expiration, which terminates a flow active during a predefined period. The second is referred to as inactive expiration. It ends a flow that is inactive during a predefined period. The last logic represents a custom expiration solution defined by the user at runtime (i.e., flow packets limit).
NFPlugins
NFPlugins are a set of NFPlugin, a user-defined extension of NFStream. An NFPlugin is instantiated using a flexible set of keyword arguments, including specific parameters or external data required for the flow feature computation (i.e., ML trained model, externally loaded C library). The flow metering process calls each NFPlugin defined by the user at three flow existence stages: initiation, update, and expiration. Thus, an NFPlugin defines a method called for each step. on_init method is called for creation with the first packet belonging to it. on_update is triggered each time a new NFPacket is mapped to the flow entry. Finally, on_expire is performed when the entry is considered expired. Consequently, extending NFStream is simple. Adding new flow features or ML model outcomes can be achieved in just a few lines.
Socket Collector
Socket collector probes the Operating System logs to construct a view of the active connections table. It is only activated when system visibility mode is set for end-host ground truth generation. The collector detects creation and closing of connections and send these state updates to the streamer.
Performance considerations: Please read current design details before considering enabling this component at scale.
Streamer
The export layer is implemented as part of the NFStreamer class. NFStreamer is the main class of the NFStream framework. It is responsible for setting the overall workflow, mainly the orchestration of parallel metering processes and the definition of the flow export format. Thus, working with flow-based data is as simple as instantiating a single class. NFStreamer is highly configurable and provides an extensive set of arguments for controlling each computation layer. NFStreamer methods define the export format of the measured flows. While it is possible to iterate over the NFStreamer object, methods include CSV file and pandas dataframe conversions. Selecting pandas format came naturally, as it is the de facto standard input format for ML frameworks. Finally, the conversion process supports features anonymization based on the Blake2 algorithm.